IPFS, or the InterPlanetary File System, is a protocol and peer-to-peer network designed to create a more distributed and efficient web. It changes how information is distributed across the internet by addressing and accessing data not through server locations (as is typical with HTTP), but through content itself. Here’s a more detailed look at how it works and its components:
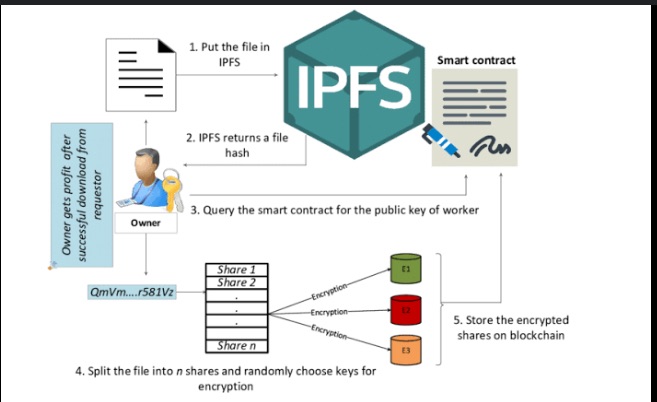
How IPFS Works
- Content Addressing: Unlike HTTP, which uses location-based addressing (URLs point to server locations), IPFS uses content-based addressing. Every piece of content on IPFS has a unique hash (a cryptographic fingerprint), and this hash is used to find and access the content. If you have the hash, you can retrieve the content from anyone who has it, not just a specific server.
- Decentralization: IPFS operates on a decentralized network where each node stores only content it is interested in, along with some indexing information that helps figure out who is storing what. This means that IPFS removes the need for centralized servers while providing a resilient and censorship-resistant way of accessing data.
- Deduplication: Since IPFS identifies content by its hash, it naturally removes duplicates across the network. If multiple nodes store the same content, they will store it under the same address, which optimizes storage space.
- Versioning and Linking: IPFS supports versioning and linking, which allows developers to build complex interconnected data structures directly in the network. This is particularly useful for version control systems, databases, and other applications where data is linked or structured.
Benefits of IPFS
- Efficiency and Speed: By fetching files from the nearest node rather than a central server, IPFS can reduce bandwidth usage and improve loading times, especially when many people are accessing the same content.
- Robustness: IPFS is designed to be resistant to node failures and network partitions. Even if parts of the network go offline, the system as a whole continues to work, ensuring data availability.
- Permanent Web: Content on IPFS can remain online as long as someone in the network is interested in hosting it. This characteristic lends itself to a more permanent web where information cannot be censored or lost easily.
Use Cases
- Distributed Applications (dApps): Many blockchain-based applications use IPFS for storing and accessing data in a way that is decentralized and immutable.
- Content Distribution: IPFS can be used for distributing large files efficiently, such as multimedia content, data from scientific research, or software updates.
- Archiving: IPFS is suitable for archiving and long-term data storage, ensuring data remains accessible far into the future.
The fundamental differences between HTTP (HyperText Transfer Protocol) and IPFS (InterPlanetary File System) stem from their underlying architectures and how they handle data delivery and storage. Here’s a concise comparison of the key aspects:
1. Addressing Content
- HTTP: Uses URLs which are location-based addresses. This means content is accessed from specific locations (servers), making the URL dependent on where the data is stored.
- IPFS: Uses content-based addressing. Content is accessed via a unique hash of its contents (cryptographic fingerprint), not its location. This means the same piece of content can be retrieved from any node in the network that has it, regardless of location.
2. Data Retrieval
- HTTP: Data is retrieved from centralized servers. If a server goes offline or is overloaded, the data may become inaccessible or slow to access.
- IPFS: Data is retrieved from a distributed network of peers. Files are broken into blocks, and nodes store only the blocks they are interested in, plus blocks they have agreed to cache. This can speed up data retrieval and reduce single points of failure.
3. Performance and Scalability
- HTTP: Scalability is achieved through infrastructure such as content delivery networks (CDNs) and load balancers, which can add complexity and cost.
- IPFS: Scalability is inherent due to its decentralized nature. The more widely a file is requested, the more it is cached and distributed, potentially improving access speed and resilience.
4. Redundancy and Caching
- HTTP: Redundancy must be manually configured via multiple server deployments or CDN services. Caching is often controlled by the server or intermediary network devices.
- IPFS: Redundancy is built into the protocol. When multiple nodes store the same data, it increases the network’s resilience. Caching happens automatically, with popular
IPFS is part of a broader movement towards a decentralized internet, aligning with other Web3 technologies and principles, and it has been increasingly adopted in various sectors that benefit from its decentralized and efficient data distribution model.

Leave a comment