A quick glance

Cloud cost refers to the total expense an organization pays to cloud providers (like AWS, Azure or Google Cloud) to use their infrastructure. Unlike traditional IT, where you buy hardware once (CapEx), cloud costs are usually OpEx (Operating Expenses) based on a pay-as-you-go model.
Key Drivers of Cloud Cost:
- Compute: Fees for running virtual servers or “instances” (charged by the second or hour).
- Storage: The cost of keeping data in the cloud (charged by the GB per month).
- Networking: “Egress” fees, or the cost of moving data out of the cloud or between regions.
- Managed Services: Additional costs for specialized tools like databases, AI models, or security features.
- Observability (Datadog, Splunk ingestion volume)
- Backup & DR
- Idle environments (Dev / UAT / Perf)
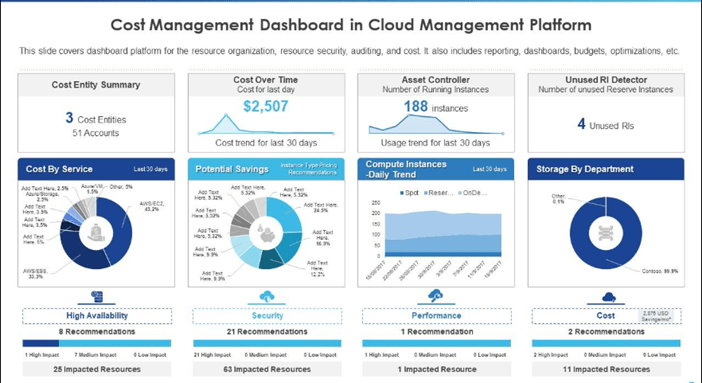
Sample Cost Dashboard
Common Optimization Strategies:
- Rightsizing: Adjusting your servers to the correct size. If you’re paying for a “Large” server but only using 10% of its power, you “rightsize” it to a “Small.”
- Eliminating “Zombie” Resources: Shutting down idle or orphaned resources (like a test server a developer forgot to turn off 3 months ago).
- Reserved Instances (RIs): Committing to use a resource for 1–3 years in exchange for a massive discount (often up to 70%).
- Spot Instances: Buying “spare” cloud capacity at a discount (up to 90%), with the trade-off that the provider can take it back if they need it.
- Auto-scaling: Setting up your system to automatically add servers during busy times and delete them when traffic is low.
Compute Optimization (Kubernetes / Microservices)
Evaluate
Improper HPA configuration, over-provisioned pods, and misaligned requests/limits lead to wasted compute capacity and hidden performance risks. Idle nodes and oversized instances with low utilization significantly inflate cloud costs, especially in non-production environments. Check if :
- HPA configured properly?
- Over-provisioned pods?
- Requests vs limits misaligned?
- Idle nodes at night?
- Large instance types with low utilization?
Techniques
Leverage VPA, Cluster Autoscaler, and Karpenter to dynamically right-size pods and nodes for optimal cost and performance. Shift stateless workloads to Spot instances and shut down non-prod clusters during off-hours to significantly reduce unnecessary cloud spend.
- Use Vertical Pod Autoscaler (VPA)
- Enable Cluster Autoscaler
- Move stateless workloads to Spot Instances
- Use Karpenter (AWS) for dynamic node right-sizing
- Turn off non-prod clusters during off-hours
Advanced Strategy
w.r.t enterprise resilience mindset there are certain key element that we need to consider. Use a balanced On-Demand and Reserved instance strategy for production to ensure resilience while optimizing long-term cost. Shift batch/ingestion workloads to Spot instances and separate ingestion, search, and API clusters to improve cost efficiency, scalability, and workload isolation.
- Keep prod on On-Demand / Reserved mix
- Move batch / capture ingestion workloads to Spot
- Separate ingestion vs search vs API clusters
Storage Optimization: Hidden Cost: S3 Versioning + Retention + Snapshots
Check whether bucket versioning is properly managed, old versions are cleaned up, and snapshots are not retained indefinitely causing hidden storage growth.
Ensure Intelligent Tiering is enabled where applicable to automatically optimize storage costs based on access patterns.
- Versioning enabled for all buckets?
- Unused old versions piling up?
- Snapshots retained indefinitely?
- Intelligent Tiering not enabled?
Network Optimization
Review inter-AZ traffic, logging overhead, and cross-zone DB replication, as these can significantly increase network costs in document platforms.
Optimize by co-locating chatty services, minimizing cross-region sync, using PrivateLink, compressing traffic, and adopting gRPC over REST where appropriate.
- Inter-AZ traffic costs
- Logging traffic
- DB cross-zone replication
Actions:
- Co-locate heavy chatty services
- Avoid unnecessary cross-region sync
- Use PrivateLink instead of public endpoints
- Compress traffic between microservices
- Use gRPC instead of REST where possible
Observability Cost
You use Datadog & Splunk — ingestion cost can explode. Observability costs in tools like Datadog and Splunk can escalate quickly due to high log ingestion, excessive debug logs, duplicate entries, and unused APM traces. Regularly review log volume per microservice and eliminate unnecessary or redundant data sources. Optimize through sampling, strict log-level governance, and well-defined retention policies. Shift from log-based to metrics-based alerting where possible — this alone can reduce cloud costs by 15–30% in many enterprises.
Evaluate:
- Log volume per microservice
- Debug logs left ON in prod?
- Duplicate logs?
- Unused APM traces?
Optimize:
- Sampling
- Log level governance
- Retention policies
- Metrics-based alerting instead of log-based where possible
This alone reduces 15–30% cloud cost in many enterprises.
Database Optimization
Database costs (e.g., Oracle for transaction logging) often rise due to over-provisioned IOPS, unnecessary Multi-AZ setups, high storage autoscale limits, and inefficient long-running queries. Regularly compare actual usage vs provisioned capacity and reassess high-availability needs for each database Optimize by moving logging databases to lower-cost tiers and partitioning large tables to improve performance. Use read replicas instead of vertical scaling and archive old logs to S3 to reduce storage and compute expenses..
Evaluate:
- IOPS provisioning vs actual usage
- Multi-AZ necessity for all DBs?
- Storage autoscale limits too high?
- Long-running queries?
Techniques:
- Move logging DB to lower tier
- Partition tables
- Use read replicas instead of scaling vertically
- Archive old logs to S3
Environment Rationalisation
Banking applications often run 4–5 environments per app, many of which remain 30% idle most of the time, driving unnecessary infrastructure costs Rationalize by merging SIT and UAT where feasible, adopting ephemeral on-demand environments, and automating weekend shutdowns. Use shared lower-environment clusters to improve utilization and reduce duplication. This approach reduces waste without impacting delivery capability or resilience.
Actions:
- Merge SIT & UAT
- Ephemeral environments (on-demand)
- Weekend shutdown automation
- Shared lower env clusters
This doesn’t reduce capability — just waste.
Advanced Strategic Levers
Move beyond infrastructure savings by introducing a Unit Cost Dashboard that tracks cost per API, per document, per GB stored, and per environment — directly linked to OKRs. Establish quarterly architecture cost reviews, similar to resilience reviews, to identify high-cost services, cost spikes by teams, and abnormal data growth. Make cost transparency a leadership metric, not just a finance concern. When cost becomes visible and measurable, behavior automatically shifts toward optimization and ownership.
1. Unit Cost Dashboard
- Cost Per API
- Cost per document stored
- Cost per GB stored
- Cost per environment
2. Architecture Cost Reviews (Quarterly)
- Which service consumes most?
- Which team spikes cost?
- Which data growth abnormal?
- Make cost visible — behavior changes.
Splunk Cost Optimation
Measure Before Cutting
Create these dashboards:
| Metric | Why |
| GB ingested per service | Identify noisy microservices |
| Log volume per environment | Lower env often wasteful |
| Debug vs Info ratio | Over-logging detection |
| Cost per 1,000 transactions | True unit economics |
Technical Optimisation Techniques
Sampling (Without Losing Visibility)
Instead of logging all API calls:
- Log 100% errors
- Sample 5–10% successful transactions
- Keep full logging only for high-risk flows
Reduce Indexed Fields
Index only:
- Transaction ID
- Consumer ID
- Document ID
- Status
Everything else → searchable but non-indexed.
Move Cold Data to Cheaper Storage
- Use SmartStore (S3-backed)
- Reduce hot bucket retention
- Archive compliance logs externally
Cloud Cost Optimization Tool Comparison (2026)
Here are some good tools available for you all to explore, majority of them are already tried and tested but every implementation is unique so please try yourself and explore feasibility on these tools.
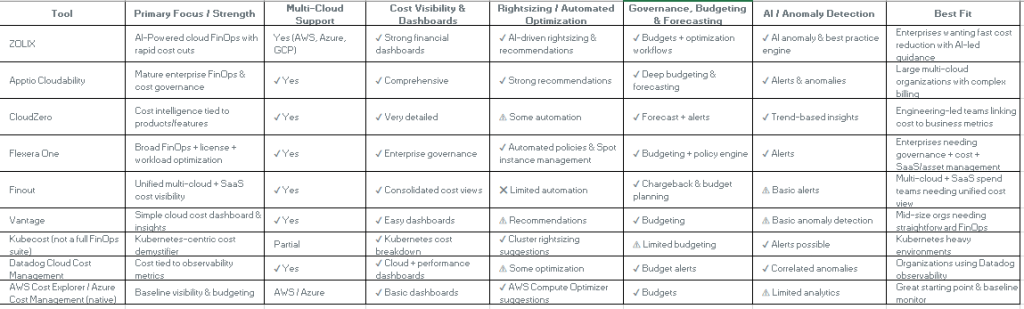
Quick Summary :
For a technology-led organization, especially in banking where scale, resilience, and compliance are critical, tracking cloud cost is as important as tracking uptime or MTTR. Without continuous monitoring, costs silently grow due to over-provisioning, idle environments, excessive logging, or architectural inefficiencies. Proactive cost governance ensures you continue leveraging cloud agility without losing financial control. Tools like AWS Cost Explorer, Azure Cost Management, Datadog, Splunk, native billing dashboards, Kubernetes cost tools (e.g., Kubecost), and FinOps platforms such as Zolix or Apptio help provide visibility, anomaly detection, forecasting, and unit-cost insights — enabling data-driven optimization rather than reactive cost cutting.

Leave a comment